Eaglescience heeft de afgelopen tien jaar bewezen een betrouwbare partner te zijn op het gebied van innovatie. Uitgeleerd zijn we echter nooit, en regelmatig komen we dingen tegen die beter kunnen. Zodra onze collega’s kansen zien voor verbetering of vernieuwing, moedigen we ze altijd aan dit idee verder uit te werken. Is het idee veelbelovend? Dan starten wij een interne pilot om dat idee tot een volwassen toepassing te maken die breed inzetbaar is. Zo vergroten we continu onze kennis en vernieuwen we onze dienstverlening door slimme toepassingen waar onze klanten en wijzelf van profiteren. In deze eerste blog over GraphQL naar SQL voor Scala zullen we starten met het delen van deze zoektocht naar innovatieve oplossingen.
Wij geloven heilig in de kracht van maatwerksoftware, omdat alleen maatwerk ons in staat stelt volledig te voldoen aan de wensen van de klant. Echter zien we in de beginfase van de ontwikkeling vaak overeenkomsten tussen verschillende projecten. Om te voorkomen dat we iedere keer het wiel opnieuw uitvinden gaan we zelf aan de slag met het ontwikkelen van slimme oplossingen. Daar leren we van en het is bovenal leuk om te doen! Eerder deden we dat door een platform voor de verwerking van (bio)sensordata, een project startup template en een interactief spel voor het trainen van AI-algoritmen te ontwikkelen. Op dit moment zijn we bezig met het abstraheren van database-toegang op een generieke manier en op een GraphQL gebaseerde techniek.
In het kort: wat is een dataflow?
De vraag ‘wat is een dataflow’ is net zo breed als de vraag ‘wat is communicatie’. In de context van webapplicaties en apps is dit de informatiestroom van de database naar de voorkant (de app of website). Om het wat duidelijker te maken geven we een paar voorbeelden: stel dat je in een webshop een lijst opvraagt van producten die in de aanbieding zijn. Iedere keer dat er een lijst met gegevens opgevraagd wordt zijn er de volgende overeenkomsten:
- Dat er informatie uit een database wordt gehaald en ontsloten naar een website;
- Dat ieder product steeds een eigen lijst met eigenschappen heeft;
- Dat zowel een webshop op enig moment een lijst met items tonen;
- Dat in vrijwel alle gevallen een complexe variatie van filtering kan worden toegepast om de betreffende informatie inzichtelijk te maken.
GraphQL
GraphQL is een querytaal voor API’s en een manier om die queries uit te voeren. GraphQL biedt de mogelijkheid om structuren te beschrijven op basis waarvan je data op wilt vragen. Een website kan een informatiebehoefte heel precies vastleggen door te refereren aan kleine onderdelen van die structuren. Bijvoorbeeld: ‘ik wil vanuit de webshop alle namen en prijzen van producten’, GraphQL geeft dan precies die data terug, zonder overbodige informatie die niet gebruikt wordt.
Onze oplossing: ‘GraphSQL’
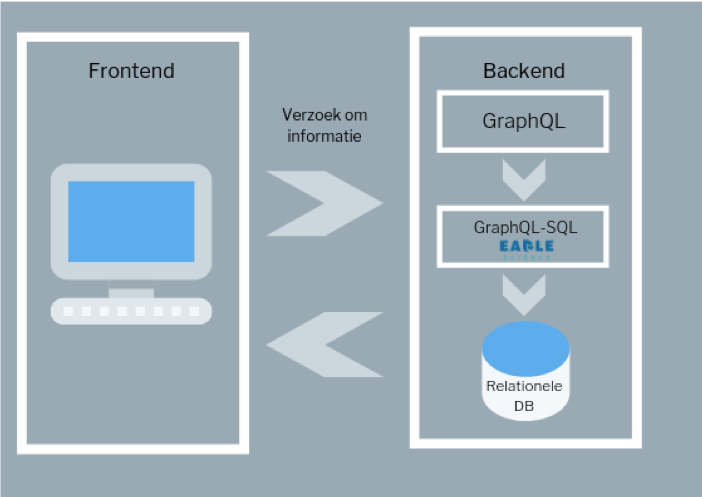
Teamleden Wessel en Bas merkten op dat in veel van onze projecten de dataflow een belangrijk onderdeel is waar op verschillende gebieden winst te behalen valt. Tot nu toe ontwikkelden wij de dataflow steeds op maat, om zo goed mogelijk af te stemmen op de specifieke functionaliteiten van het betreffende product. Maar op een hoger abstractieniveau werden patronen herkend, waardoor Wessel en Bas voorstelden om intern een losstaande component te ontwikkelen. Meerdere projecten zouden bij deze generieke oplossing gebaat zijn doordat het ontwikkelproces versnelt en er zo ruimte gecreëerd wordt voor het ontwikkelen van nieuwe functionaliteiten.
Door deze data qua structuur door middel van GraphQL in te richten zien we dat er winst behaald kan worden op het gebied van efficiëntie in ontwikkeltijd, maar ook qua netwerkefficiëntie omdat er minder onnodig dataverkeer plaatsvindt. Door de informatiebehoefte met GraphQL te formuleren kan deze automatisch omgezet worden naar een query voor een database. Daarmee kun je de hele informatiestroom van database naar cliënt, over de complete development stack die wij gebruiken, op een generieke manier invullen. Dit doen we door de informatiestroom op twee onderdelen te optimaliseren: het eerste deel wordt verbeterd door het gebruik van GraphQL, en het tweede door een generieke vertaling naar de efficiënte database queries te maken en zo de vraag van de gebruiker te beantwoorden.
Dit wordt nu als bibliotheek ontwikkeld zodat onze collega’s niet steeds het wiel opnieuw hoeven uit te vinden en zich volledig kunnen toeleggen op het ontwikkelen van nieuwe features die van toegevoegde waarde zijn voor onze klanten.